
KI-Agenten stoßen an ihre Grenzen — und die gesamte AI-Branche reagiert. Die Lösung heißt Subagenten. Statt einem einzigen, überforderten KI-Agenten arbeiten jetzt mehrere spezialisierte Agenten parallel an komplexen Aufgaben. Anthropic, OpenAI, Google und Microsoft setzen bereits auf diese neue Architektur. In diesem Artikel erfährst du, warum Subagenten so viel besser arbeiten als einzelne Agenten, wie die Technik dahinter funktioniert und was das für dein Unternehmen bedeutet.
Was sind Subagenten?
Subagenten sind spezialisierte KI-Agenten, die von einem übergeordneten Agenten gesteuert werden. Der übergeordnete Agent — oft Orchestrator oder Lead Agent genannt — zerlegt eine komplexe Aufgabe in kleinere Teilschritte. Jeden Teilschritt übergibt er an einen eigenen Subagenten.
Jeder Subagent hat sein eigenes Context Window. Er arbeitet isoliert an seiner Aufgabe. Am Ende liefert er nur eine kompakte Zusammenfassung zurück. Der Orchestrator sammelt diese Ergebnisse und fügt sie zusammen.
Das Prinzip kennt jeder aus dem Büro-Alltag. Ein Projektleiter verteilt Aufgaben an Experten im Team. Jeder Experte kümmert sich um seinen Bereich. Am Ende trägt der Projektleiter die Ergebnisse zusammen. Genau so funktionieren KI-Subagenten.
Der entscheidende Unterschied zu einem normalen Tool-Aufruf: Ein Subagent ist selbst ein vollständiger Agent. Er kann planen, Tools verwenden und eigene Schlüsse ziehen. Er arbeitet autonom — aber innerhalb klar definierter Grenzen. Sobald seine Aufgabe erledigt ist, übergibt er das Ergebnis und beendet sich.
Warum brauchen wir Subagenten?

Das Problem liegt im sogenannten Context Window. Jeder KI-Agent hat ein begrenztes Fenster, in dem er Informationen verarbeiten kann. Aktuelle Modelle bieten bis zu 200.000 Tokens. Das klingt nach viel — reicht aber oft nicht.
Der Grund: die Transformer-Architektur. Jeder Token muss auf jeden anderen Token achten. Je mehr Tokens im Context liegen, desto dünner verteilt sich die Aufmerksamkeit. Das nennt sich das n²-Problem.
Ab etwa 100.000 Tokens arbeiten KI-Agenten noch zuverlässig. Ab 150.000 Tokens häufen sich Fehler. Der Agent vergisst frühere Entschlüsse. Er wählt falsche Tools. Er halluziniert Parameter, die es gar nicht gibt. Ab rund einer Million Tokens erreicht jedes Modell seine Leistungsgrenze — ganz gleich, wie groß das Context Window ist.
Context Pollution: Wenn der Agent den Überblick verliert
Dieses Phänomen trägt einen Namen: Context Pollution. Der Context des Agenten wird mit irrelevanten Daten überflutet. Das führt zu konkreten Problemen:
Der Agent wählt falsche Tools und erfindet Parameter dazu. Er verliert seinen Determinismus — gleiche Eingaben liefern plötzlich unterschiedliche Ergebnisse. Die Kosten steigen, weil aufgeblähte Prompts mehr Tokens verbrauchen.
Stell dir vor, du arbeitest an einem Schreibtisch. Anfangs liegt dort nur dein aktuelles Projekt. Du arbeitest fokussiert und effizient. Dann stapeln sich Dokumente aus zehn verschiedenen Projekten auf deinem Tisch. Du findest nichts mehr. Du greifst zum falschen Ordner. Du vergisst, was du gerade erledigen wolltest. Genau das passiert einem KI-Agenten mit überladenem Context.
Wie lösen Subagenten das Problem?
Die Antwort lautet: Context-Isolation. Statt alles in einen einzigen Context zu packen, bekommt jeder Subagent sein eigenes, sauberes Fenster.
Ein typisches Setup sieht so aus: Der Orchestrator behält nur etwa 30.000 Tokens. Er steuert und koordiniert. Drei bis fünf Subagenten erhalten jeweils 40.000 bis 50.000 Tokens für ihre spezifische Aufgabe — etwa Recherche, Code oder Tests.
Jeder Subagent arbeitet in seinem isolierten Context. Er verbraucht intern seine Tokens für die Aufgabe. Zurück an den Orchestrator schickt er nur eine kompakte Zusammenfassung von wenigen tausend Tokens.
Das Ergebnis: Jeder Context bleibt klein und fokussiert. Kein Agent wird mit fremden Daten belastet. Die Qualität steigt drastisch.
Die 83%-Rechnung: So viel Context sparen Subagenten
Eine konkrete Beispielrechnung zeigt den Effekt. Bei einer typischen MCP-Tool-Suche verbraucht ein Subagent intern rund 51.000 Tokens. Zurück an den übergeordneten Agenten sendet er nur etwa 8.500 Tokens.
Das bedeutet: 83 Prozent der Tokens bleiben im Subagenten. Sie belasten den Orchestrator nicht. 42.500 Tokens werden komplett vom Parent-Context ferngehalten.
Beim Vergleich eines Refactoring-Tasks wird der Unterschied noch deutlicher. Ohne Subagenten braucht ein einzelner Agent 150.000 Tokens. Die Leistung leidet. Die Kosten liegen bei etwa 1,50 Dollar pro Task. Die Qualität: mittelmäßig.
Mit Subagenten verteilt sich die Arbeit. Der Orchestrator nutzt 30.000 Tokens. Vier parallele Worker erhalten je 50.000 Tokens. Die Kosten sinken auf rund 0,80 Dollar. Über 90 Prozent der Tokens sind günstige Cache-Reads. Und das Tempo? Vier Mal schneller.
Token-Ökonomie: Warum Subagenten günstiger sind
Die Token-Ökonomie von Subagenten folgt einem klaren Muster. Für jeden Token, den ein Agent schreibt, liest er etwa 165 Tokens. Das Lese-Schreib-Verhältnis liegt bei 165:1.
Entscheidend dabei: Über 90 Prozent aller gelesenen Tokens stammen aus dem Prompt Cache. Der Preis dafür beträgt nur 0,50 Dollar pro Million Tokens. Das macht Multi-Agent-Systeme wirtschaftlich erst richtig attraktiv.
Der direkte Vergleich zeigt es: Ein einzelner Task, der ohne Subagenten 4,80 Dollar kostet, schlägt mit Subagenten nur mit 0,35 Dollar zu Buche. Das ist 14 Mal günstiger. Diese Zahlen stammen aus realen Tests bei der Entwicklung mit Tools wie Claude Code.
Für Unternehmen bedeutet das: Die höhere Anzahl an Token-Aufrufen wird durch den Cache-Effekt mehr als ausgeglichen. Subagenten verbrauchen zwar insgesamt mehr Tokens als ein einzelner Chat. Aber die meisten davon sind billige Cache-Reads — nicht teure neue Berechnungen.
+90,2 %: Die Performance-Zahlen von Anthropic
Die beeindruckendste Zahl kommt von Anthropic selbst. In internen Tests übertraf ein Multi-Agent-System mit Claude Opus 4 als Lead Agent und Claude Sonnet 4 als Subagenten einen einzelnen Claude Opus 4 Agenten um 90,2 Prozent.
Das ist kein marginaler Gewinn. Das ist fast eine Verdopplung der Leistung. Besonders bei breit angelegten Recherche-Aufgaben zeigten Subagenten ihre Stärke. Sie konnten mehrere Richtungen parallel erkunden, während ein einzelner Agent sequenziell arbeiten musste.
Die Analyse ergab außerdem: 80 Prozent der Leistungsschwankungen lassen sich allein durch die Token-Nutzung erklären. Wer mehr Tokens sinnvoll auf separate Agenten verteilt, bekommt bessere Ergebnisse. Das bestätigt den Kern der Subagenten-Architektur.
Interessant ist auch der Modell-Effekt: Ein Upgrade auf ein stärkeres Subagenten-Modell brachte größere Zugewinne als eine schlichte Verdopplung des Token-Budgets beim gleichen Modell. Die Qualität der Subagenten zählt also mehr als deren Quantität.
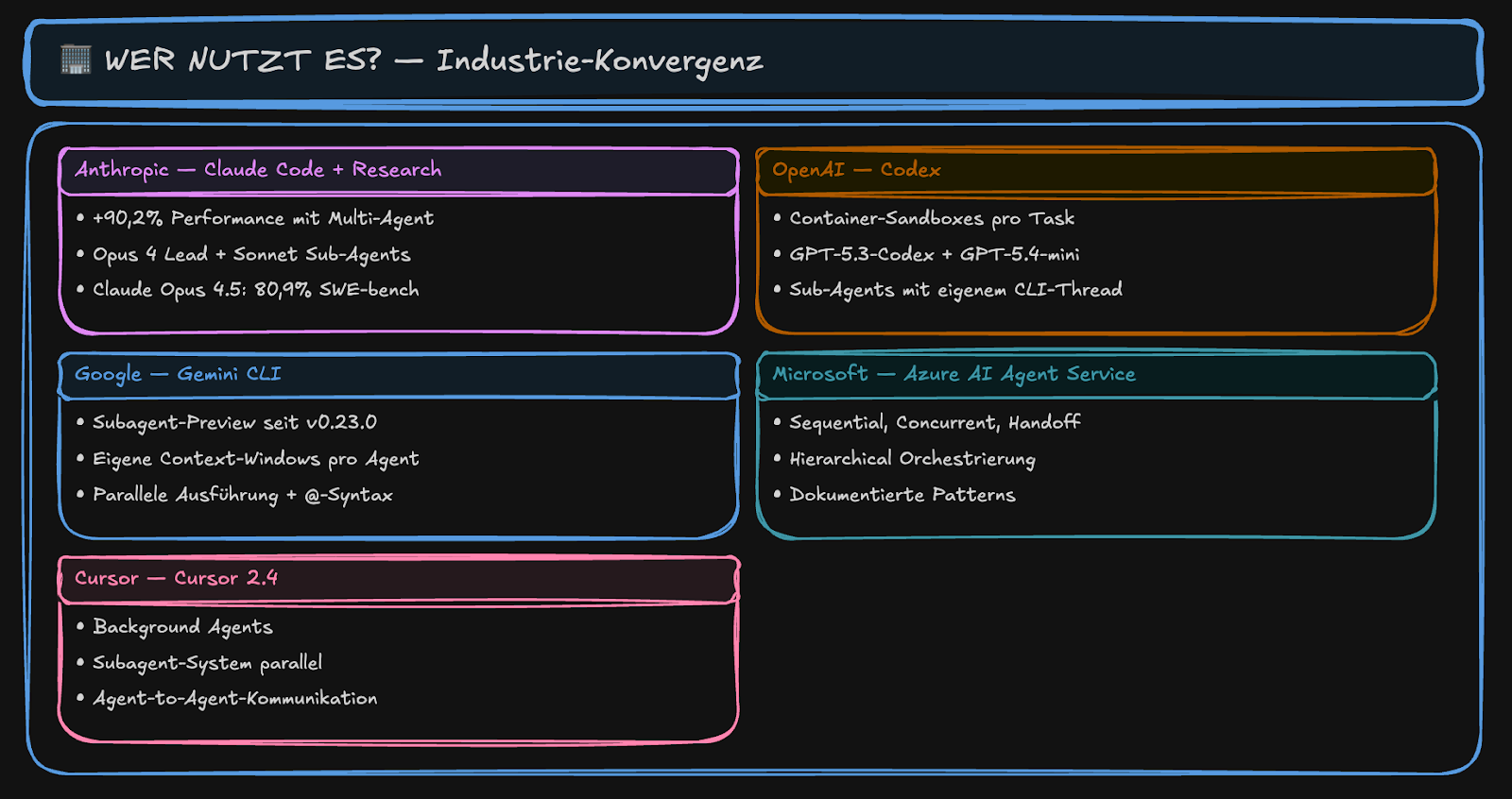
Welche Unternehmen setzen auf Subagenten?
Die gesamte AI-Industrie konvergiert auf dieses Muster. Hier ein Überblick über die wichtigsten Akteure:
Anthropic setzt bei Claude Code und seinem Research-Feature auf Subagenten. Opus 4 fungiert als Lead Agent. Sonnet-Modelle übernehmen als Subagenten die Teilaufgaben. Mit Claude Opus 4.5 erreichte Anthropic 80,9 Prozent auf dem SWE-bench.
OpenAI nutzt dasselbe Prinzip bei Codex. Jeder Task läuft in einer eigenen Container-Sandbox. GPT-5.3-Codex arbeitet als Haupt-Modell. GPT-5.4-mini erledigt als Subagent die kleineren Jobs. Jeder Subagent bekommt seinen eigenen CLI-Thread.
Google hat mit Gemini CLI ab Version 0.23.0 eine Subagent-Preview eingeführt. Jeder Agent erhält sein eigenes Context Window. Die Agenten arbeiten parallel und lassen sich per @-Syntax ansprechen. Auch Googles ADK (Agent Development Kit) bietet fertige Patterns für parallele und sequenzielle Subagenten.
Microsoft bietet über den Azure AI Agent Service drei Muster an: Sequential, Concurrent und Handoff. Die hierarchische Steuerung ist dokumentiert und sofort einsetzbar. Ergänzend dazu liefert das AutoGen-Framework von Microsoft Research flexible Koordination für Multi-Agent-Systeme.
Cursor hat mit Version 2.4 Background Agents vorgestellt. Das Subagent-System arbeitet parallel. Agenten können direkt miteinander sprechen — nicht nur über den Orchestrator.
Wer selbst KI-Agenten im Unternehmen aufbauen möchte, findet hier eine gute Grundlage für die Architekturwahl.
Die vier Architektur-Patterns für Subagenten
Die Industrie hat sich auf vier grundlegende Muster geeinigt. Jedes passt zu anderen Aufgaben.
Orchestrator-Worker ist das verbreitetste Muster. Ein zentraler Agent verteilt Aufgaben an spezialisierte Worker. Die Worker arbeiten parallel. Der Orchestrator sammelt die Ergebnisse ein (Fan-Out / Fan-In). Claude Code und OpenAI Codex nutzen dieses Pattern. Es bietet hohe Kontrolle bei gleichzeitiger Geschwindigkeit.
Hierarchical Agents fügen eine weitere Ebene ein. Ein Manager delegiert an Supervisors. Die Supervisors steuern ihre eigenen Worker-Teams. Jede Ebene hat ihren eigenen Context. Das eignet sich für große, komplexe Projekte mit vielen Beteiligten. Claude Agent und Team-Systeme setzen auf dieses Muster.
Swarm Pattern arbeitet ohne zentrale Kontrolle. Die Agenten koordinieren sich selbst als Peer-to-Peer-Netzwerk. Daraus entsteht eine emergente Koordination. Dieses Muster eignet sich besonders für kreative Aufgaben, bei denen die optimale Lösung nicht vorhersehbar ist. OpenAI Swarm und ähnliche Frameworks nutzen diesen Ansatz.
Pipeline Pattern reiht Agenten hintereinander auf. Jeder Agent erledigt eine Stufe: Code schreiben, Review durchführen, Tests ausführen, Deployment starten. CI/CD-Workflows und QA-Prozesse nutzen dieses sequenzielle Muster. Es ist das einfachste Pattern — aber auch das am leichtesten zu debuggen.
Die Software-Metapher: Vom Monolith zu Microservices
Die Parallele zur Softwareentwicklung ist frappierend. Vor 15 Jahren baute jedes Unternehmen monolithische Anwendungen. Ein einziger Codeblock erledigte alles. Irgendwann wurde der Monolith zu groß, zu langsam, zu fehleranfällig.
Die Lösung hieß Microservices. Statt eines großen Blocks arbeiteten viele kleine, spezialisierte Dienste zusammen. Jeder Dienst hatte seine eigene Datenbank, seinen eigenen Speicher, seine eigene Logik.
Bei KI-Agenten passiert gerade dasselbe. Der Single Agent ist der Monolith. Er versucht, alles in einem Context zu erledigen. Subagenten sind die Microservices der KI-Welt. Jeder hat seinen eigenen Context, seine eigene Aufgabe, seine eigene Verantwortung.
Die Formel lautet: Spezialisierung + Isolation + Parallel-Arbeit = bessere Ergebnisse. Das galt für Software. Das gilt jetzt für KI.
Und genau wie bei Microservices bringt die neue Architektur nicht nur Vorteile. Die Komplexität steigt. Die Kommunikation zwischen den Teilen muss sauber funktionieren. Fehler in einem Subagenten dürfen nicht das ganze System lahmlegen. Deshalb brauchen Subagenten-Systeme klare Schnittstellen, robuste Fehlerbehandlung und durchdachte Steuerung — genau wie gut gebaute Microservices.
Marktprognosen: Wo steht die Branche?
Die Zahlen sprechen eine klare Sprache. Gartner prognostiziert, dass bis Ende 2026 rund 40 Prozent aller Enterprise-Apps eingebettete, aufgabenspezifische KI-Agenten enthalten werden. 2025 lag dieser Anteil noch unter fünf Prozent. Das ist ein Sprung um den Faktor acht innerhalb eines einzigen Jahres.
Der Markt für KI-Agenten wächst laut Analysten mit einer jährlichen Wachstumsrate von 43 Prozent (CAGR). Capgemini beziffert den durchschnittlichen ROI von Agentic AI auf 171 Prozent. Bis 2035 könnte Agentic AI laut Gartner rund 30 Prozent des Umsatzes mit Business-Software ausmachen — über 450 Milliarden Dollar.
Gleichzeitig warnt Gartner: Über 40 Prozent der Agentic-AI-Projekte könnten bis Ende 2027 eingestellt werden — wegen unklarer Geschäftsziele, zu hoher Kosten oder mangelnder Risiko-Kontrolle. Der Schlüssel liegt also nicht darin, einfach Agenten einzusetzen. Sondern darin, sie gezielt und strategisch zu nutzen.
Diese Zahlen zeigen: Subagenten sind kein Nischen-Thema. Sie werden zum Standard der KI-Branche.
Subagenten in der Praxis: Ein konkretes Beispiel
Stell dir eine Recherche-Aufgabe vor. Du willst alle Vorstandsmitglieder der IT-Firmen im S&P 500 finden. Ein einzelner Agent müsste hunderte Webseiten sequenziell durchsuchen. Das dauert Stunden und der Context quillt über.
Mit Subagenten läuft es anders. Der Lead Agent teilt die Aufgabe auf: Fünf Subagenten recherchieren jeweils einen Teil der Firmen. Sie arbeiten gleichzeitig. Jeder Subagent sucht, filtert und fasst zusammen. Innerhalb von Minuten liegen alle Ergebnisse vor.
Anthropic berichtet, dass diese Parallel-Arbeit die Recherche-Dauer um bis zu 90 Prozent verkürzt. Was vorher Stunden brauchte, erledigen Subagenten in wenigen Minuten.
Ein weiteres Beispiel aus der Software-Entwicklung: Ein Team will eine große Code-Basis refaktorisieren. Ein einzelner Agent müsste tausende Dateien lesen, verstehen und ändern. Sein Context wäre sofort überlastet. Mit Subagenten teilt der Orchestrator die Arbeit auf. Ein Subagent analysiert die Backend-Logik. Ein anderer prüft die Frontend-Komponenten. Ein dritter schreibt und führt Tests durch. Alle arbeiten gleichzeitig in ihren eigenen Sandboxes.
Rakuten berichtet von einem Fall, bei dem Claude Code eine komplexe Aufgabe über eine Code-Basis mit 12,5 Millionen Zeilen in sieben Stunden erledigte — mit 99,9 Prozent numerischer Genauigkeit. Ohne parallele Subagenten wäre das in diesem Zeitrahmen nicht machbar gewesen.
Das Konzept lässt sich auf viele Bereiche übertragen — von der Code-Entwicklung über Datenanalysen bis hin zu KI-gestützten Telefon-Assistenten, die komplexe Kundenanfragen an spezialisierte Sub-Routinen weiterleiten.
Wann lohnen sich Subagenten — und wann nicht?
Subagenten sind nicht immer die beste Wahl. Aktuelle Forschung zeigt: Bei sequenziellen Aufgaben, die strikt aufeinander aufbauen, können Multi-Agent-Systeme die Leistung sogar verschlechtern. Der Koordinations-Aufwand frisst das Leistungsplus.
Google Research hat dies in einer Studie mit 180 verschiedenen Agenten-Konfigurationen bestätigt. Bei Finanzanalysen — einer typisch parallelen Aufgabe — verbesserte die zentrale Multi-Agent-Architektur die Leistung um über 80 Prozent. Bei streng sequenziellen Planungs-Aufgaben sank die Leistung dagegen um bis zu 70 Prozent.
Die klare Empfehlung lautet: Starte mit einem einzelnen, gut konfigurierten Agenten. Optimiere ihn, bis er an seine Grenzen stößt. Erst dann lohnt sich der Schritt zu Subagenten.
Subagenten rechnen sich bei parallel bearbeitbaren Aufgaben. Beispiele: breite Recherchen, Code-Reviews mit mehreren Perspektiven, Tests verschiedener Hypothesen oder die gleichzeitige Bearbeitung mehrerer Dateien.
Die Faustregel: Lässt sich die Aufgabe in unabhängige Teilstücke zerlegen? Dann profitierst du von Subagenten. Hängt jeder Schritt vom vorherigen ab? Dann bleib beim einzelnen Agenten.
So baust du dein erstes Subagenten-System
Der Einstieg ist einfacher als gedacht. Viele Plattformen bieten bereits fertige Subagenten-Muster an.
Schritt 1: Wähle einen Anbieter. Claude Code, OpenAI Codex oder Gemini CLI bieten native Subagenten-Unterstützung. Alternativ nutzt du Frameworks wie LangGraph oder CrewAI.
Schritt 2: Definiere den Orchestrator. Er braucht klare Regeln: Welche Aufgaben darf er delegieren? Wie viele Subagenten darf er starten? Wann stoppt er?
Schritt 3: Gestalte die Subagenten. Jeder Subagent bekommt einen fokussierten Prompt, eigene Tools und ein begrenztes Context Window. Weniger ist mehr.
Schritt 4: Lege fest, was zurückkommt. Subagenten sollen nur kompakte Zusammenfassungen liefern. Keine Rohdaten. Keine vollen Protokolle. Nur das Wesentliche.
Schritt 5: Teste und optimiere. Subagenten-Systeme verhalten sich anders als einzelne Agenten. Kleine Prompt-Änderungen können große Effekte haben. Überwache die Token-Kosten und die Qualität der Ergebnisse.
Häufige Fehler beim Einsatz von Subagenten
Auch bei Subagenten gibt es typische Stolperfallen. Anthropic berichtet aus eigener Erfahrung:
Frühe Versionen starteten 50 Subagenten für einfache Fragen. Die Lösung: klare Regeln für die Anzahl der Subagenten pro Aufgabe.
Subagenten suchten endlos nach Quellen, die gar nicht existierten. Die Lösung: Zeitlimits und maximale Schrittzahlen.
Agenten lenkten sich gegenseitig mit Updates ab. Die Lösung: Subagenten arbeiten isoliert und liefern nur am Ende ihr Ergebnis.
Ein weiterer häufiger Fehler: Zu viele Daten fließen zwischen den Agenten hin und her. Der Orchestrator bekommt statt einer knappen Zusammenfassung den vollen Output. So entsteht dieselbe Context Pollution, die Subagenten eigentlich verhindern sollen. Anthropic empfiehlt deshalb ein Artefakt-System: Subagenten speichern ihre Ergebnisse extern und übergeben nur leichte Referenzen.
Der wichtigste Grundsatz: Prompt Engineering wird bei Subagenten-Systemen noch kritischer als bei einzelnen Agenten. Jede Formulierung beeinflusst das Zusammenspiel des gesamten Systems. Anthropic berichtet, dass ein eigens entwickelter Tool-Testing-Agent die Aufgabenzeit künftiger Agenten um 40 Prozent senkte — allein durch bessere Tool-Beschreibungen.
Fazit: Subagenten definieren die Zukunft der KI
Subagenten lösen eines der größten Probleme aktueller KI-Systeme: den überlaufenden Context. Durch Isolation, Spezialisierung und Parallel-Arbeit steigern sie die Leistung um bis zu 90 Prozent, senken die Kosten um den Faktor 14 und beschleunigen komplexe Aufgaben um das Vierfache.
Die gesamte AI-Industrie — von Anthropic über OpenAI bis Google — setzt auf diese Architektur. Gartner prognostiziert, dass 40 Prozent aller Enterprise-Apps bis Ende 2026 mit KI-Agenten ausgestattet sein werden. Subagenten bilden das technische Rückgrat dieser Entwicklung.
Für Unternehmen bedeutet das: Wer KI-Agenten einsetzen will, kommt an Subagenten nicht vorbei. Die Technik ist verfügbar, die Patterns sind erprobt und die Ergebnisse sind messbar besser.
Du willst tiefer einsteigen? Auf unserem YouTube-Kanal Everlast AI erklären wir regelmäßig die neuesten Entwicklungen rund um KI-Agenten, Subagenten und Multi-Agent-Systeme — praxisnah und auf Deutsch.

























.webp)

.png)























%20(1).png)








.png)









































